First of all, to finish the classification tasks, we need a train function to train the data.
/**
* @brief Train the input data by softmax algorithm
* @param train Training data, input contains one\n
* training example per column
* @param labels The label of each training example
*/
template<typename T>
void softmax<T>::train(const Eigen::Ref<const EigenMat> &train,
const std::vector<int> &labels)
{
//#1 generate unique labels, because we need the
//NumClass and generate the ground truth table
auto const UniqueLabels = get_unique_labels(labels);
auto const NumClass = UniqueLabels.size();
//#2 initialize weight and gradient
weight_ = EigenMat::Random(NumClass, train.rows());
grad_ = EigenMat::Zero(NumClass, train.rows());
//#3 initialize ground truth
auto const TrainCols = static_cast<int>(train.cols());
EigenMat const GroundTruth = get_ground_truth(NumClass, TrainCols,
UniqueLabels,
labels);
//#4 create the random generator for mini-batch algorithm
std::random_device rd;
std::default_random_engine re(rd());
int const Batch = (get_batch_size(TrainCols));
int const RandomSize = TrainCols != Batch ?
TrainCols - Batch - 1 : 0;
std::uniform_int_distribution<int>
uni_int(0, RandomSize);
for(size_t i = 0; i != params_.max_iter_; ++i){
auto const Cols = uni_int(re);
auto const &TrainBlock =
train.block(0, Cols, train.rows(), Batch);
auto const >Block =
GroundTruth.block(0, Cols, NumClass, Batch);
//#5 compute the cost of the cost function
auto const Cost = compute_cost(TrainBlock, weight_, GTBlock);
//#6 break the loop if meet the criteria
if(std::abs(params_.cost_ - Cost) < params_.epsillon_ ||
Cost < 0){
break;
}
params_.cost_ = Cost;
//#7 compute gradient
compute_gradient(TrainBlock, GTBlock);
//#8 update weight
weight_.array() -= grad_.array() * params_.lrate_;
}
}
The most complicated part is #5 and #7, other part is trivial. To make #5 work, I need to finish the cost function(graph_00) and gradient descent(graph_01).
 |
| graph_00 |
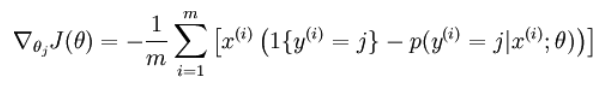 |
| graph_01 |
 terms before computing the exponential, this is trivial to be done in Eigen.
terms before computing the exponential, this is trivial to be done in Eigen.template<typename T>
void softmax<T>::compute_hypothesis(Eigen::Ref<const EigenMat> const &train,
Eigen::Ref<const EigenMat> const &weight)
{
hypothesis_.noalias() = weight * train;
max_exp_power_ = hypothesis_.colwise().maxCoeff();
for(size_t i = 0; i != hypothesis_.cols(); ++i){
hypothesis_.col(i).array() -= max_exp_power_(0, i);
}
hypothesis_ = hypothesis_.array().exp();
weight_sum_ = hypothesis_.array().colwise().sum();
for(size_t i = 0; i != hypothesis_.cols(); ++i){
if(weight_sum_(0, i) != T(0)){
hypothesis_.col(i) /= weight_sum_(0, i);
}
}
//prevent feeding 0 to log function
hypothesis_ = (hypothesis_.array() != 0 ).
select(hypothesis_, T(0.1));
}
After I have the hypothesis matrix, I can compute the cost and the gradient at ease.
template<typename T>
double softmax<T>::compute_cost(const Eigen::Ref<const EigenMat> &train,
const Eigen::Ref<const EigenMat> &weight,
const Eigen::Ref<const EigenMat> &ground_truth)
{
compute_hypothesis(train, weight);
double const NSamples = static_cast<double>(train.cols());
return -1.0 * (hypothesis_.array().log() *
ground_truth.array()).sum() / NSamples +
weight.array().pow(2.0).sum() * params_.lambda_ / 2.0;
}
template<typename T>
void softmax<T>::compute_gradient(Eigen::Ref<const EigenMat> const &train,
Eigen::Ref<const EigenMat> const &weight,
Eigen::Ref<const EigenMat> const &ground_truth)
{
grad_.noalias() =
(ground_truth.array() - hypothesis_.array())
.matrix() * train.transpose();
auto const NSamples = static_cast<double>(train.cols());
grad_.array() = grad_.array() / -NSamples +
params_.lambda_ * weight.array();
}
The test results could see on this post.
No comments:
Post a Comment