Contours is a convenient and powerful tools in computer vision, with it, we can achieve many interesting tasks, like analyze the famous tic-tac-toe(pic00) game. Original tutorial of PyImageSearch do not show us how to detect the X lie in the center, in this example I try to do that with the help of cv::approxPolyDP.
 |
| pic00--Tic-tac-toe |
How could contour help us analyze this picture? Well, we can begin with the properties of contours.
1 : contour area, which equal to the pixel number of the contour
2 : convex hull, smallest possible pixel enclosing contour.More mathematically, it is a minimum set which contain the set X(in our case, it is contour) in euclidean space. Convex hull can be found by greedy algorithm, but that is another topic, let us back to tic-tac-toe
3 : solidity == (contour area) / (convex hull area), this value will <= 1 since the area of contour area will never greater than convex hull area.
Now we have all the tools, let us party.
Step 1 : Parse command line
std::string parse_command_line(int argc, char **argv)
{
using namespace boost::program_options;
try
{
options_description desc{"Options"};
desc.add_options()
//set up --help or -h to show help information
("help,h", "Help screen")
//set up --image or -i as a required argument
//to store the name of image
("image,i", value()->required(), "Image to process");
//parse the command line and store it in containers
variables_map vm;
store(parse_command_line(argc, argv, desc), vm);
if (vm.count("help")){
std::cout<<desc<<'\n';
return {};
}else{
return vm["image"].as<std::string>();
}
//the magic to make the other required arguments
//become optional if the users input "help"
notify(vm);
}
catch (const error &ex)
{
std::cerr << ex.what() << '\n';
}
return {};
}
This part is fairly easy, just give boost program options a try, you will find out that parsing command line options by c++ is a piece of cake. To run this program, open your command prompt and enter command like "tic_tac_toe.exe --image ../tic_tac_toe/tic_tac_toe_small.jpg". Make sure your pc know where to find the dll/so.
Step 2 : Preprocessing
cv::Mat preprocess(cv::Mat &color_img)
{
//resize the image to width 480 and keep the aspect ratio
ocv::resize_aspect_ratio(color_img, color_img, {480, 0});
//find coutours need a binary image, so we must
//transfer the origin img to binary image.
cv::Mat gray_img;
cv::cvtColor(color_img, gray_img, CV_BGR2GRAY);
//this would not copy the value of gray_img but create a new header
//I declare an alias to make code easier to read
cv::Mat binary_img = gray_img;
cv::threshold(gray_img, binary_img, 0, 255,
CV_THRESH_BINARY_INV | CV_THRESH_OTSU);
cv::Mat const Kernel =
cv::getStructuringElement( cv::MORPH_RECT, {5,5});
cv::morphologyEx(binary_img, binary_img, cv::MORPH_CLOSE, Kernel);
return binary_img;
}
Pretty standard preprocess, resize the image(codes can find at here), binarize it and use morphology to remove some small holes.
 |
| pic01--Binary image of tic-tac-toe |
Step 3 : Find contour
std::vectorcontour_vec; //findContours will change the input image, provide a copy if you //want to resue original image. In pyimage serach guru, //it use CV_RETR_EXTERNAL, but this will omit inner //contour, to detect center X we need to retrieve deeper contour cv::findContours(binary_img, contour_vec, CV_RETR_CCOMP, CV_CHAIN_APPROX_SIMPLE);
Find the contour of , to get the center contour of X, we have to declare it as CV_RETR_CCOMP.
Step 4 : Show the properties of contours
Contour get_approx_poly(Contour const &contour)
{
Contour poly_contour;
double const Epsillon = cv::arcLength(contour, true) * 0.02;
bool const Close = true;
cv::approxPolyDP(contour, poly_contour, Epsillon, Close);
return poly_contour;
}
void print_contour_properties(Contour const &contour)
{
double const ContourArea = cv::contourArea(contour);
Contour convex_hull;
cv::convexHull(contour, convex_hull);
double const ConvexHullArea = cv::contourArea(convex_hull);
auto const BoundingRect = cv::boundingRect(contour);
Contour const Poly = get_approx_poly(contour);
std::cout<<"Contour area : "<<ContourArea<<std::endl;
std::cout<<"Aspect ratio : "<<
(BoundingRect.width / static_cast(BoundingRect.height))
<<std::endl;
std::cout<<"Extend : "<<ContourArea/BoundingRect.area()<<std::endl;
std::cout<<"Solidity : "<<ContourArea/ConvexHullArea<<std::endl;
std::cout<<"Poly size : "<<Poly .size()<<", is convex "
<<std::boolalpha<<cv::isContourConvex(Poly)<<std::endl;
std::cout<<std::endl;
}
void show_contours_properties(cv::Mat const &input,
std::vector<Contour> const &contour_vec)
{
cv::Mat input_cpy;
for(size_t i = 0; i != contour_vec.size(); ++i){
input.copyTo(input_cpy);
cv::Scalar const Color{255};
int const ThickNess = 3;
cv::drawContours(input_cpy, contour_vec,
static_cast<int>(i), Color, ThickNess);
print_contour_properties(contour_vec[i]);
auto const WindowName = "contour " + std::to_string(i);
cv::imshow(WindowName, input_cpy);
cv::waitKey();
//without this line, previous contour image will not be closed
//before the program end
cv::destroyWindow(WindowName);
}
}
This step will analyze the properties of contours, print them out on the command prompt with the detected contour image(pic02).
 |
| pic02--Properties of contour |
Step 5 : Recognize the type of contour
ContourType recognize_countour_type(Contour const &contour)
{
double const ContourArea = cv::contourArea(contour);
Contour const Poly = get_approx_poly(contour);
ContourType type = ContourType::unknown;
if((Poly .size() > 7 && Poly .size() < 10) && ContourArea > 1000){
type = ContourType::o_type;
}else if(Poly .size() >= 10 && ContourArea < 10000){
type = ContourType::x_type;
}
return type;
}
According to the properties shown by print_contour_properties, we could recognize the X and O by the size of approximate polygon and contour area.
Step 6 : Draw X and O on the image
void write_x_and_o(cv::Mat const &input,
std::vector<Contour> const &contour_vec)
{
cv::Mat input_cpy = input.clone();
std::string const TypeName[] = {"X", "O"};
for(size_t i = 0; i != contour_vec.size(); ++i){
ContourType type = recognize_countour_type(contour_vec[i]);
if(type != ContourType::unknown){
cv::Scalar const Color{255};
int const ThickNess = 3;
cv::drawContours(input_cpy, contour_vec, static_cast(i),
Color, ThickNess);
auto point = cv::boundingRect(contour_vec[i]).tl();
point.y -= 10;
double const Scale = 1;
cv::putText(input_cpy, TypeName[static_cast(type)],
point, cv::FONT_HERSHEY_COMPLEX, Scale, Color,
ThickNess);
}
}
cv::imshow("result", input_cpy);
cv::waitKey();
}
The last step is fairy easy, draw out X and O on the original image and verify the result(pic03).
 |
| pic03--Result |
The source codes could be found at github
As PyimageSearch mentioned, there are another solutions, like machine learning, if I haven't read the tutorial, I may jump to the route of picking up machine learning from my tool box(ex : give dlib a try). Same as programming, pick easier solution first, keep things simple and stupid unless you cannot avoid more complicated solutions. This is one of the reason why all of my posts avoid old-style c or c with classes, because they are too verbose, easier to commit errors, harder to debug, maintain, low level codes do not mean the compiler will generate faster and smaller binary(In contrast, they could be slower and buggier) .





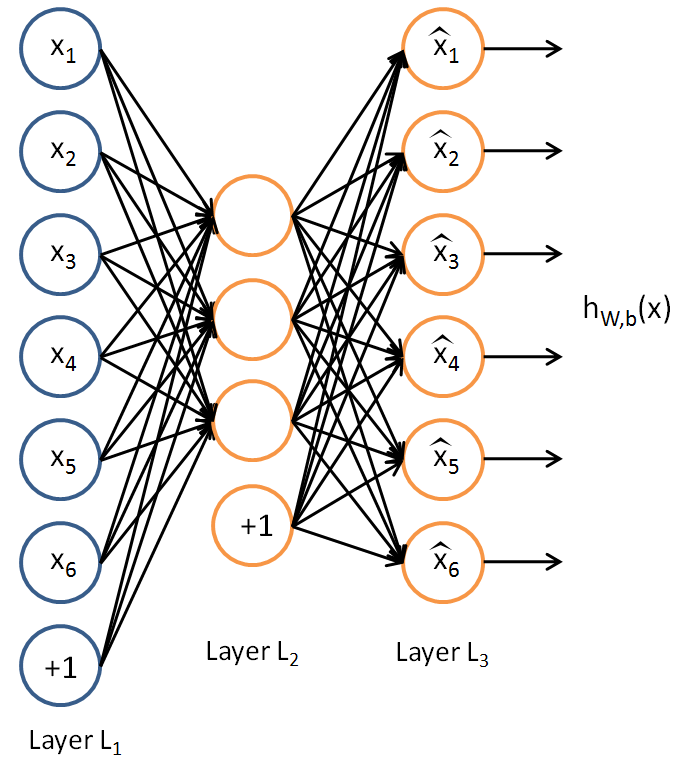


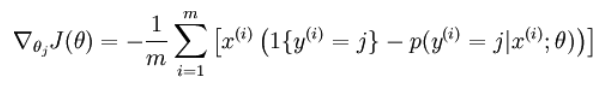
 terms before computing the exponential, this is trivial to be done in Eigen.
terms before computing the exponential, this is trivial to be done in Eigen.