Extract meaningful features from interesting object(ex : cat, dog, smoke, car, human face, bird and so on) is crucial, because it can
dominate the prediction results. But as you can see, find out good features from the images may not an easy task and always require expertise knowledge, you may need to study tons of papers before you can decided which kind of features you should feed into the machine learning algorithms.Deep learning give use another option, rather than extract the features by human, deep learning
let the computer figure out which features to use.
The idea of deep learning could be explain by graph_00
 |
| graph_00 |
To tell you the truth, the first time I know there are some algorithms could extract features for us, I am very exciting about it. Not to mention there are many research results already proved that deep learning is a very powerful beast in the field of image recognition, in order to leverage the power of deep learning, I begin to study the tutorial of
UFLDL before I use
shark(shark is quite easy to compile on unix, linux, mac and windows, but could be
very slow without atlas) and
caffe(I do not know this one is easier to compile or not when I write this post, but the performance of caffe is awesome) to help me finish the tasks, because this could help me gain more sense about what are those algorithms doing about.
The first deep learning algorithm introduced by
UFLDL is
sparse autoencoder, the implementation details of sparse autoencoder is quite daunting, even it may be the most easiest algorithm to understand in the deep learning algorithms.
At the first glance, sparse autoencoder looks quite similar to the traditional neural network, the different part are
- It is train layer by layer
- The dimension of the hidden layers usually less than the input layers
- Sparse autoencoder add sparsity constraint on the hidden unit(autoencoder do not have this constraint)
- The purpose of sparse autoencoder is find out how to use less features to reconstruct the input
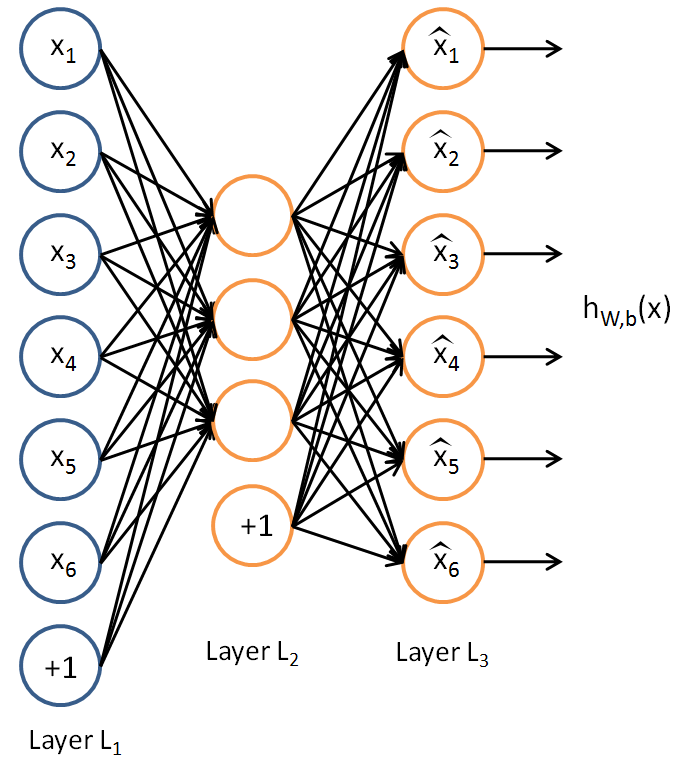
Autoencoder(or sparse autoencoder) is combine with three layers(graph_01), there are input layer, hidden layer and output layer.
 |
| graph_01 |
The output of the hidden layers are the features we want to feed into the other machine learning algorithms(ex : svm, random forest, softmax regression and so on) for classification tasks. Sometimes we also say the output of the hidden layers are "encoder", the output of the output layer are "decoder", because the hidden layer will extract the features from input layer, the output layer will reconstruct the input by the output of the hidden layer.
The meaning of train it layer by layer is that we can use the output of the hidden layer as the next input of the autoencoder layer(this autoencoder also contain three layers). By this way we can build efficient deep network.
The implementation details of sparse autoencoder of mine can be found at
here, the
example and the
images file. graph_02 show the results train by my implementation. Since the mini-batch do not work well in this case, I need to use the full batch size to do the gradient descent, without algorithm like L-BFGS, the speed could be quite slow. In the next post, I will use shark to recognize the hand written digts from MNIST.
 |
| graph_02 |
Atlas is difficult to build on windows and is
not well optimized for Windows 64
bit, if you want to get maximum speed from shark, better train the data under unix/linux.
No comments:
Post a Comment